

















【Unity】射线检测
2D射线检测
Collider2D无法被3D射线检测,必须使用Physics2D
射线检测不是特别方便Debug,无法看到射线的范围,则可以使用Collider协助:
- 创建一个
BoxCollider2D - 勾选
IsTrigger,这样就不会有碰撞了 - 设置
Layer层级
1 | private void ButtressCheck(BoxCollider2D coll) |
如此一来,这个Box检测就与coll的位置、大小一摸一样,scene中coll的绿色范围就代表着BoxCase的位置和大小
创建并使用射线
射线检测:从某个初始点开始,沿着特定的方向发射一条不可见且无限长的射线,通过此射线检测是否有任何模型添加了Collider碰撞器组件。一旦检测到碰撞,停止射线继续发射。
Collider组件中Is Trigger选项的开关并不影响射线检测
! 对了还有一个参数,写在Raycast末尾,QueryTriggerInteraction(指定该射线是否应该命中触发器),上面我说过Is Trigger选项的开关不影响射线检测,但是前提是QueryTriggerInteraction该参数设置为检测触发器了,你也可以将该参数设置为仅对碰撞器进行检测,这个参数可以全局设置。
举两个常用的例子
- 根据物体的指向确定射线的方向
Ray ray = new Ray(transform.position, transform.forward); - 根据鼠标的位置确定射线的方向
Ray ray = Camera.main.ScreenPointToRay(Input.mousePosition);
1 | [] private float eventDistance = 3f; |
显示射线
Uniyt中通过使用
Debug.DrawLine()和Debug.DrawRay()都可以让射线现出原形。
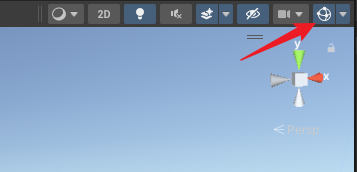
但是!需要特别注意的是,这里画出的线其实跟射线毫无关联的,因为就算没有射线,这里也能画出线来。两点一线,只要确定两个点就行了。所以这里的线只是辅助开发者而已。
但是!又需要特别注意的是,如果你的射线不显示的话,估计是因为!我就是刚刚不小心把它关了,然后挠头找不到原因,我已经犯了好几次这样的错误了!!!!!这个按钮主要是用于显示和关闭场景中的辅助图形之类的(如灯光,射线、摄像机等)!
两种方法的区别
DrawLine:真正的两点确定一条线DrawRay:从初始点出发画一条线,所以需要一个初始点,加上一个具有方向和长度的向量,就得到一条射线
一般使用DrawRay,比较贴合射线的性质。而DrawRay也有两种常用方法
1 | // 直接了当的设置射线的起点和方向 |
实际运用
筛选能击中的物体
可以通过物体的Layer控制射线需要击中的物体
如果有两种物体A,B,则可以将其的Layer设置为对应的LayerA和LayerB。
射线只想要击中A,而不受B的影响,可以将LayerMask设置为LayerA
1 | [] private float eventDistance = 3f; |
让射线穿透
如果有两个A在一条线上,发出射线时永远只会返回离玩家最近的那个A,如何返回后面的A呢?
可以将前面的A的Layer设置为成为LayerB,这样射线就不会返回前面的A了。
1 | hit.collider.gameObject.layer = 10; // 这里数字10代表的是Layer的第10层 |
让射线检测多个
通过上面的学习我们知道可以通过RaycastHit结构体获得检测到的碰撞体,但似乎每次只能返回一个,如何一次返回在该条射线上所有符合标准的物体呢?
1 | [] private float eventDistance = 3f; |
拓展
LayerMask的介绍
LayerMask 实际上是一个位码操作,在Unity3D中一共有32个Layer层,并且不可增加。
位运算符
按位运算符:~、|、&、^。位运算符主要用来对二进制位进行操作。
逻辑运算符:&&、||、!。逻辑运算符把语句连接成更复杂的复杂语句。
按位运算符:左移运算符<<,左移表示乘以2,左移多少位表示乘以2的几次幂。
例如:var temp = 14 << 2; 表示十进制数14转化为二进制后向左移动2位。
temp最后计算的值为 14乘以2的平方,temp = 56;
同理,右移运算符>>,移动多少位表示除以2的几次幂。
LayerMask的使用
1 | LayerMask mask = 1 << 3; // 表示开启Layer3。 |
1 | LayerMask mask = ~(1<<2|1<<8); // 表示关闭Layer2和Layer8。 |
1 | LayerMask mask = 1 << LayerMask.NameToLayer(“TestLayer”); // 表示开启层名“TestLayer” 的层 。 |
RaycastHit的point属性
该point的属性表达的是射线与碰撞体的交点,一般运用在moba游戏人物的移动等。
【Git】拉取部分文件
拉取部分文件
使用Sparse Checkout
- 使用
git init初始化仓库 - 使用
git remote add origin [远程仓库地址]将远程仓库添加到本地仓库 - 使用
git config core.sparsecheckout true将Git配置为使用sparse checkout模式 - 编辑
.git/info/sparse-checkout文件来指定需要拉取的目录 - 使用
git pull origin [分支名]拉取代码
使用Submodule
Submodule:将一个仓库设置为另一个仓库的子项目
- 使用
git submodule add [子项目仓库地址] [子项目路径]命令将子项目仓库添加到主项目 - 通过
git submodule init初始化子项目 - 使用
git submodule update更新子项目代码
【Unity】函数执行顺序
单独物体
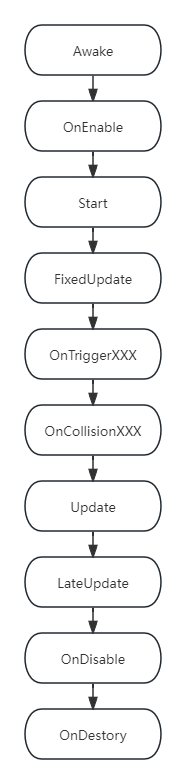
单独物体同一脚本内
常用函数执行顺序如下图:
单独物体不同脚本内
空节点物体按先后顺序添加三个脚本SequenceA、SequenceB、SequenceC
脚本内容格式如下:
1 | using UnityEngine; |
输出:
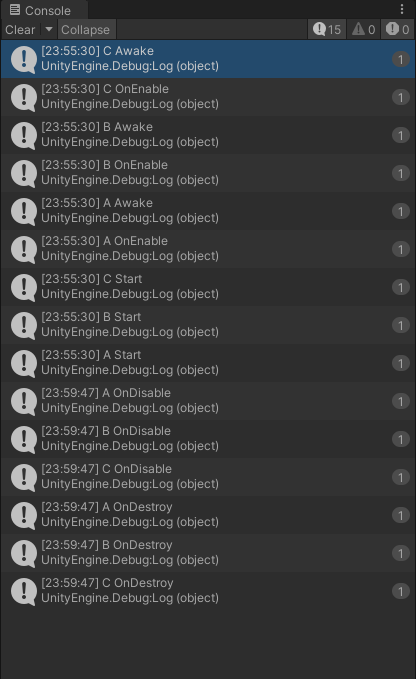
C Awake –> C OnEnable –> B Awake –> B OnEnable –> A Awake –> A OnEnable –> C Start –> B Start –> A Start –> A OnDisable –> B OnDisable –> C OnDisable –> A OnDestory –> B OnDestory –> C OnDestory
小结:
Awake、OnEnable这两个函数基本上是绑定在一块的,要执行一起执行,其他的函数则按照基础函数周期顺序执行
Awake、OnEnable、Start优先执行后挂接的脚本;OnDisable、OnDestroy优先执行先挂接的脚本同一物体不同脚本的函数(例如
Awake、Start)执行顺序只与挂接脚本时间的先后有关(后来先到),与脚本的层级关系无关
在正规项目中,为了控制脚本之间的执行顺序,一般会使用一个管理脚本来控制各个脚本之间的执行顺序。
使用脚本控制各个脚本执行顺序
创建空节点物体,其名称为Sequence,挂接如下脚本
1 | using Unity.VisualScripting; |
输出如下:
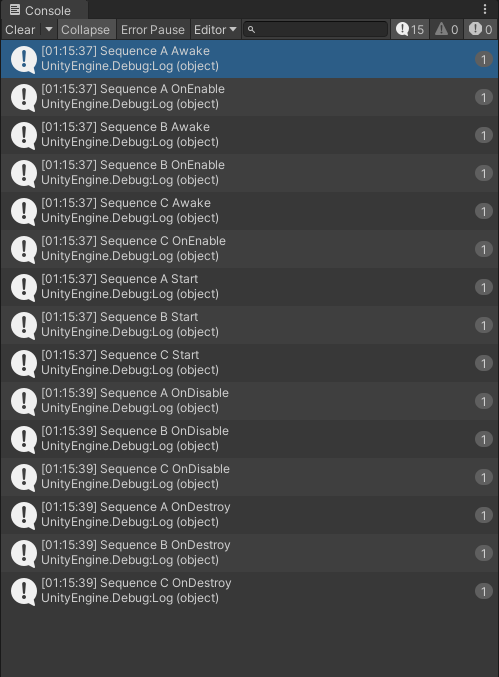
使用管理脚本控制脚本之间各个函数的执行顺序与直接挂接不一样:不同脚本的函数是完全按照基础顺序执行,没有后来先到的说法
多个物体
多个物体同一脚本
先后创建三个空节点,名称分别为:函数执行顺序01、函数执行顺序02、函数执行顺序03
三个物体都挂接SequenceA脚本,为了能区分log是哪个物体发出的,微调了一下脚本,如下:
1 | using UnityEngine; |
输出:
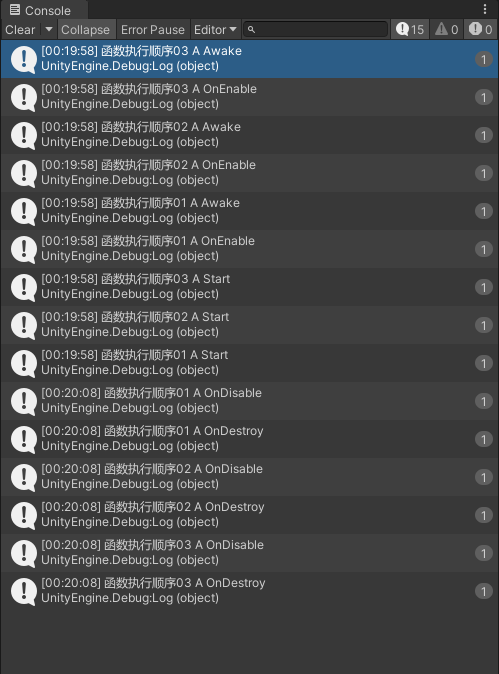
小结:
Awake、OnEnable这两个函数基本上是绑定在一块的,要执行一起执行,其他的函数则按照基础函数周期顺序执行Awake、OnEnable、Start优先执行后挂接的脚本;OnDisable、OnDestroy优先执行先挂接的脚本- 不同物体的同一脚本的函数执行顺序同样只与挂接脚本的时间先后有关,与物体创建的时间先后、物体层级、物体父子节点无关
使用脚本控制各个脚本执行顺序
创建一个空节点物体,挂接一个脚本,通过控制脚本的创建子物体和添加脚本的时机,来观察输出,判断函数执行顺序
实验组:
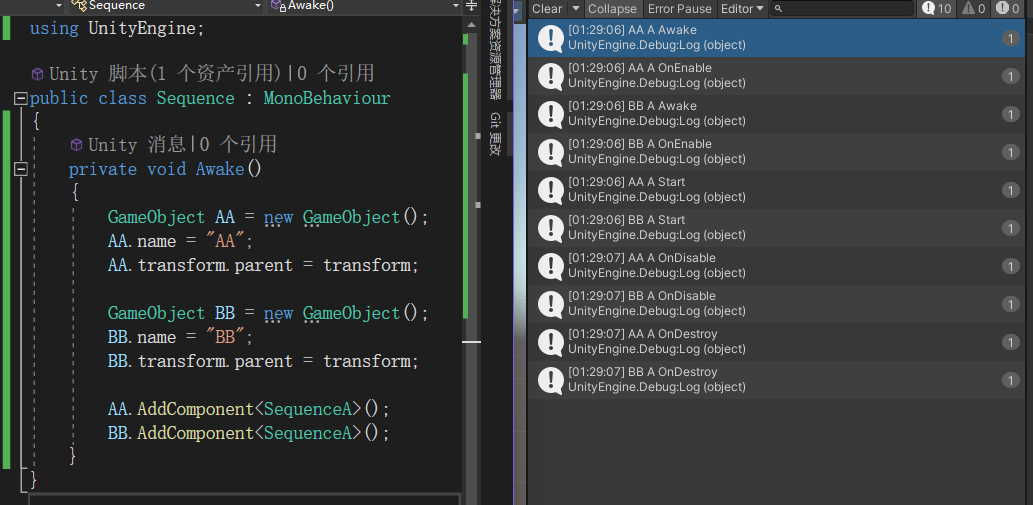
对照组一(改变物体的创造的先后顺序):
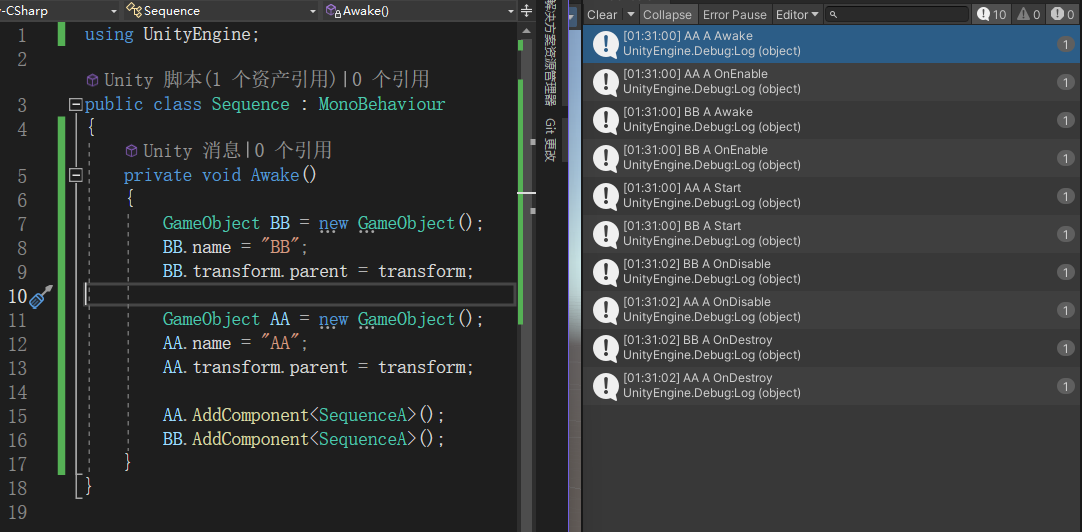
对照组二(改变物体添加脚本的先后顺序):
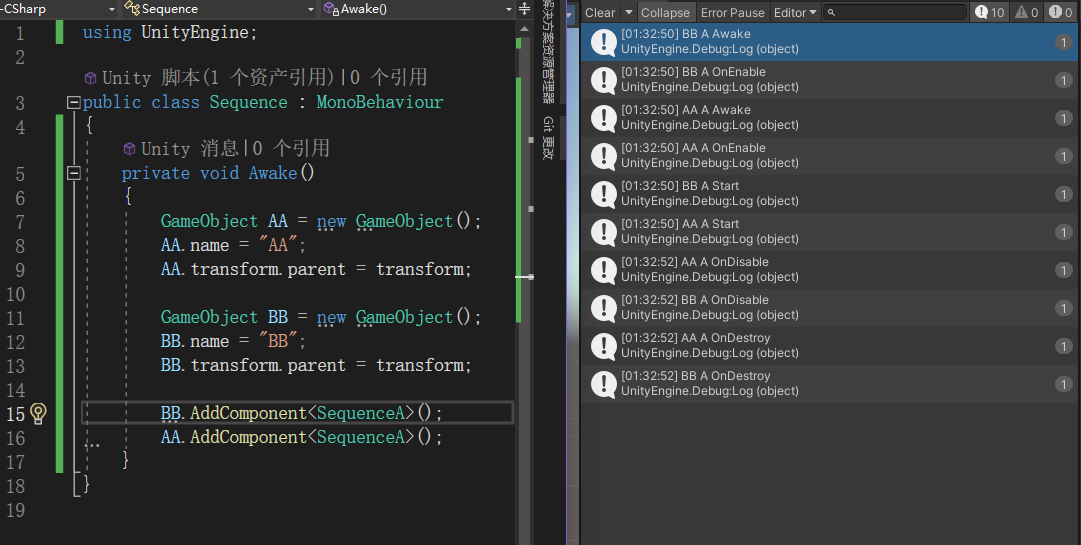
通过对照组一得出结论:
OnDisable、OnDestroy两个函数的执行先后顺序与该脚本所挂接物体创造的先后时间有关,先创建的物体优先执行通过对照组二得出结论:
Awake、OnEbable、Start三个函数的执行先后顺序与脚本的添加时间有关,先添加的脚本先执行
总结
可以将函数大致分为两大类
OnDisable、OnDestroy的执行顺序只与该脚本的创建时间有关,先创建的先执行。(无需考虑是否在同一物体、是使用脚本方法AddComponent创建还是使用Inspector创建)- 注:经过测试发现,如果是不同物体的不同脚本这两个函数的执行顺序不可控,完全随机(如α物体挂载A脚本,β物体挂载B脚本)。
Awake、OnEnable、Start需要在两种情况下考虑- 使用
Inspector创建:需要考虑挂载脚本的时间先后顺序,后挂载的脚本先执行(后来先到) - 使用
AddComponent创建:先创建的脚本优先执行
- 使用


【lua】lua学习笔记
Lua安装
- 下载lua环境
- 将文件解压到任意路径下
- 将2中的路径设置为电脑的全局变量
Lua数据类型
| 数据类型 | 描述 |
|---|---|
| nil | 无效值 |
| boolean | false和true |
| number | 双精度类型的实浮点数 |
| string | 字符串类型,使用单引号或双引号表示 |
| function | 由C或lua编写的函数 |
| userdata | 表示任意存储在变量中的C的数据结构 |
| thread | 表示执行的独立线路,用于执行协同程序 |
| table | Lua中的表(table)其实是一个”关联数组”(associative arrays),数组的索引可以是数字、字符串或表类型。在 Lua 里,table 的创建是通过”构造表达式”来完成,最简单构造表达式是{},用来创建一个空表。 |
对table的索引使用方括号[]外还可以使用.
1 | tlb = {"aa", "bb", "cc"} |
注:
在lua中只有nil表示false,0表示true
在lua中序列号从1开始
Lua变量
Lua 变量有三种类型:全局变量、局部变量、表中的域
Lua 中的变量全是全局变量,哪怕是语句块或是函数里,除非用 local 显式声明为局部变量
局部变量的作用域为从声明位置开始到所在语句块结束
变量的默认值均为 nil
可以和pytohn一样,赋值时可以一次赋值多个变量
1 | a, b = 10x, x*x |
常用作交换变量,或将函数调用返回给变量
1 | a, b = b, a |
Lua循环
while循环
1 | a = 10 |
for循环
数值for循环
1 | for var=exp1,exp2,exp3 do |
var 从 exp1 变化到 exp2,每次变化以 exp3 为步长递增 var,并执行一次 **”执行体”**。exp3 是可选的,如果不指定,默认为1
1 | for i = 1, 10, 1 do |
泛型for循环
泛型for循环通过一个迭代器函数来遍历所有值,类似于C#中的foreach语句
1 | --打印数组a的所有值 |
拓展:
将上述的
ipairs替换成pairs是一样的结果,但他们的实现却有些不同ipairs适用于数组(i估计是integer的意思),pairs适用于对象,因为数组也是对象,所以pairs用于数组也没问题。
详细可看Lua的for in和pairs
repeat...until循环
重复执行循环,直到指定的条件为真为止
1 | a = 10 |
Lua流程控制
1 | a = 11 |
注:Lua中的0为true
Lua函数
可变参数
1 | function add(...) |
注:可变参数直接传入值与传入表的用法不一样
select("#", ...)可以用在表和值#...只能用在表上
1 | -- 传入表 |
1 | -- 传入值 |
select()函数
select("#", ...)返回可变参数的长度select(n, ...)用于返回从起点n开始到结束为止的所有参数列表a = select(n, ...)将参数列表索引为n的参数赋值给a
1 | function f(...) |
遍历select(n, ...)
无法直接使用for循环直接遍历select(n, ...)所返回的数据
需要获取到返回数据的长度,然后再通过索引号获取数据中的元素
1 | function f(...) |
table表
类似于python中的集合
索引从1开始
当我们获取 table 的长度的时候无论是使用
#还是table.getn其都会在索引中断的地方停止计数,而导致无法正确取得 table 的长度。如tbl = {[1] = 2, [2] = 6, [3] = 34, [26] =5}的长度为3。
表的常用方法:
| 方法 | 用途 |
|---|---|
table.concat(table[,sep[,start[,end]]]) |
将表从start到end以sep分隔符隔开,使用时需注意 |
table.insert(table,[pos,]value) |
在pos位置插入元素,pos参数可选,默认尾部插入 |
table.remove(table[,pos]) |
移除元素,pos参数可选,默认尾部 元素 |
table.sort(table[,comp]) |
将表升序排序 |
注意:
在使用
table.concat方法时,表需要有正确的格式才能正确显示。错误的格式:
2
3
4
5
6
7
8
9
tlb = {[1] = "aa", [2] = "bb", [3] = "cc", [10] = "dd"}
print(table.concat(tlb, ",")) -- 输出aa,bb,cc
-- 错误格式二:序号为非数字
tlb = {[1] = "aa", foo = "bb", [3] = "cc"}
print(table.concat(tlb, ",")) -- 输出aa
模块与包
创建一个模块就是创建一个table,将需要导出的常量、函数放入其中
创建模块
1 | -- 创建一个module.lua的文件 |
访问模块
1 | -- 创建一个test.lua的文件 |
Metatable元表
设置元表
1 | -- 方法一 |
返回元表
1 | getmetatable(mytable) |
__index元方法
当你通过键来访问 table 的时候,如果这个键没有值,那么Lua就会寻找该table的metatable(假定有metatable)中的__index 键。如果__index包含一个表格,Lua会在表格中查找相应的键。
1 | other = {foo = 3} |
__index可以包含一个函数,函数的参数固定为table和键
1 | tlb = setmetatable({key1 = "value1"}, { |
总结:
Lua 查找一个表元素时的规则,其实就是如下 3 个步骤:
- 1.在表中查找,如果找到,返回该元素,找不到则继续
- 2.判断该表是否有元表,如果没有元表,返回 nil,有元表则继续。
- 3.判断元表有没有 __index 方法,如果 __index 方法为 nil,则返回 nil;如果 __index 方法是一个表,则重复 1、2、3;如果 __index 方法是一个函数,则返回该函数的返回值。
__newindex元方法
当你给表的一个缺少的索引赋值,解释器就会查找__newindex 元方法:如果存在则调用这个函数而不进行赋值操作。
1 | -- 当__newindex=table时 |
1 | -- 当__newindex=函数时,将table、键、值代入函数 |
拓展:
rawset(table, key, value)方法:在不触发任何元方法的情况下将table[index]设为value(即不受__newindex的影响
rawget(table, index)方法:同上,在不触发任何元方法的情况下获取table[index](即不受__index的影响
2
3
4
5
6
7
8
9
10
11
12
13
14
local tableB = {NUM = 100}
local tableC = {}
setmetatable(tableA, {__index = tableB, __newindex = tableC})
print(tableA.NUM) -- 输出100
print(rawget(tableA,"NUM")) -- 输出nil
tableA.NAME = "AA"
print(tableA,NAME) -- 输出nil
print(tableC.NAME) -- AA
rawset(tableA, "NAME", "I AM AA")
print(tableA.NAME) -- 输出I AM AA
表的操作符
类似于python的魔法方法
| 模式 | 描述 |
|---|---|
| __add | 对应的运算符’+’ |
| __sub | 对应的运算符 ‘-‘ |
| __mul | 对应的运算符 ‘*’ |
| __div | 对应的运算符 ‘/‘ |
| __mod | 对应的运算符 ‘%’ |
| __unm | 对应的运算符 ‘-‘ |
| __concat | 对应的运算符 ‘..’ |
| __eq | 对应的运算符 ‘==’ |
| __lt | 对应的运算符 ‘<’ |
| __le | 对应的运算符 ‘<=’ |
定义表的相加
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
-- 自定义计算表中最大键值函数 table_maxn,即返回表最大键值
function table_maxn(t)
local mn = 0
for k, v in pairs(t) do
if mn < k then
mn = k
end
end
return mn
end
-- 两表相加操作
mytable = setmetatable({ 1, 2, 3 }, {
__add = function(mytable, newtable)
for i = 1, table_maxn(newtable) do
table.insert(mytable, table_maxn(mytable)+1,newtable[i])
end
return mytable
end
})
secondtable = {4,5,6}
mytable = mytable + secondtable
for k,v in ipairs(mytable) do
print(k,v)
end
__tostring元方法
__tostring元方法用于修改表的输出行为
1 | mytable = setmetatable({ 10, 20, 30 }, { |
协程
| 方法 | 描述 |
|---|---|
| coroutine.create() | 创建 coroutine,返回 coroutine, 参数是一个函数,当和 resume 配合使用的时候就唤醒函数调用 |
| coroutine.resume() | 重启 coroutine,和 create 配合使用 |
| coroutine.yield() | 挂起 coroutine,将 coroutine 设置为挂起状态,这个和 resume 配合使用能有很多有用的效果 |
| coroutine.status() | 查看 coroutine 的状态 注:coroutine 的状态有三种:dead,suspended,running,具体什么时候有这样的状态请参考下面的程序 |
| coroutine.wrap() | 创建 coroutine,返回一个函数,一旦你调用这个函数,就进入 coroutine,和 create 功能重复 |
| coroutine.running() | 返回正在跑的 coroutine,一个 coroutine 就是一个线程,当使用running的时候,就是返回一个 coroutine 的线程号 |
1 | function foo() |
以上实例中,我们定义了一个名为 foo 的函数作为协同程序。在函数中,我们使用 coroutine.yield 暂停了协同程序的执行,并返回了一个值
在主程序中,我们使用 coroutine.create 创建了一个协同程序对象,并使用 coroutine.resume 启动了它的执行。
在第一次调用 coroutine.resume 后,协同程序执行到 coroutine.yield 处暂停,并将值返回给主程序。然后,我们再次调用 coroutine.resume,并传入一个值作为协同程序恢复执行时的参数。
执行以上代码输出结果为:
1 | 协同程序 foo 开始执行 |
local value = coroutine.yield("暂停 foo 的执行")的作用:
挂起协程,时协程暂停
将
"暂停 foo 的执行"返回给启动这次协程的coroutine.resume再次启动协程时获取参数赋值给value
【Unity】限制相机移动范围
将该脚本挂载到拥有BoxCollider组件的GameObject上,设置包围盒的大小范围即可限制主相机的移动范围
1 | using System.Collections; |
【Unity】本地化日志
方法一
通过Application.logMessageReceived事件,控制log的输出及方法
1 | using Sirenix.OdinInspector; |
方法二
自定义log类,通过自定义类的方法输出并本地化日志
该方法自定义自定义性更强,可以过滤命名空间
1 | using System; |
【Unity】【CSharp】堆与栈
值类型和引用类型
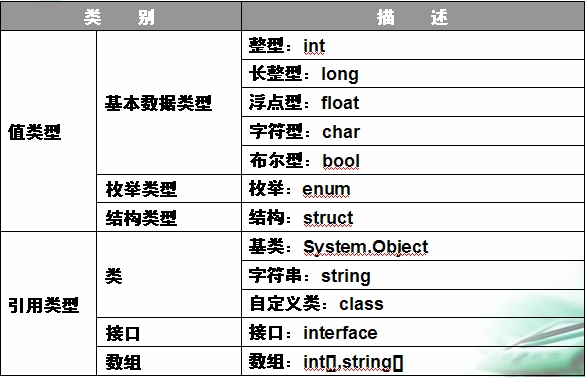
值类型和引用类型的存储方式
- 引用类型:引用类型存储在堆中。类型实例化的时候,会在堆中开辟一部分空间存储类的实例。类对象的引用还是存储在栈中。
- 值类型:值类型总是分配在它声明的地方,做为局部变量时,存储在栈上;类对象的字段时,则跟随此类存储在堆中。
1 | class Program |
值类型和引用类型的区别
- 引用类型和值类型都继承自Systerm.Object类。不同之处,值类型则是继承Systerm.Object的子类Systerm.ValueType类,而几乎所有的引用类型都是直接从Systerm.Object继承。
- 我们在给引用类型的变量赋值的时候,其实只是赋值了对象的引用;而给值类型变量赋值的时候是创建了一个副本(副本不明白?说通俗点,就是克隆了一个变量,即python中的深拷贝)。
1 | class Program |
值类型和引用类型的内存分配情况
1 | class Program |
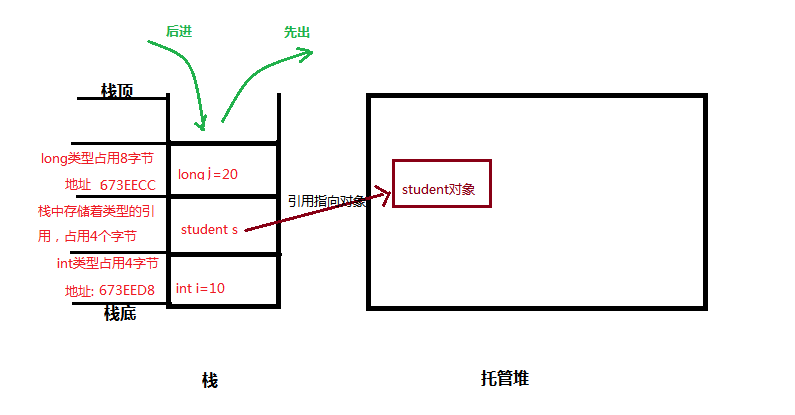
栈的结构是后进先出,也就是说:变量j的生命周期在变量s之前结束,变量s的生命周期在变量i之前结束,
栈地址从高往底分配
类型的引用也存储在栈中
堆与栈的详细介绍
搞不明白堆和栈的叫法?
堆:在c里面叫堆,在c#里面其实叫托管堆。
栈:就是堆栈,因为和堆一起叫着别扭,就简称栈了。
托管堆
托管堆不同于堆,它是由CLR(公共语言运行库(Common Language Runtime))管理,当堆中满了之后,会自动清理堆中的垃圾。所以,做为.net开发,我们不需要关心内存释放的问题。
搞不清楚内存堆栈与数据结构堆栈?
- 数据结构堆栈:是一种后进先出的数据结构,它是一个概念,图4-1中可以看出,栈是一种后进先出的数据结构。
- 内存堆栈:存在内存中的两个存储区(堆区,栈区)。
- 栈区:存放函数的参数、局部变量、返回数据等值,由编译器自动释放
- 堆区:存放着引用类型的对象,由CLR释放